
 Digital Analytics Expert
Digital Analytics Expert HTML, CSS & JS Lover
HTML, CSS & JS Lover Apps Script Developer
Apps Script Developer Problem-Solving Oriented
Problem-Solving Oriented



Il campionamento è una vera e propria tecnica statistica. Per campione statistico si intende quel gruppo di unità elementari (sottoinsieme particolare della popolazione) individuato in modo da consentire, con un rischio definito di errore, la generalizzazione all’intera popolazione.
Per fare un esempio pratico, se volessi stimare il numero di alberi in una zona di 100 ettari (con distruzione degli alberi piuttosto uniforme), potrei contare il numero di alberi in 1 ettaro e moltiplicarlo per 100. Va da se che, molto probabilmente, ogni ettaro non conterrà lo stesso numero di alberi, per cui il totale ottenuto dalla stima di cui sopra è soggetto ad errore. Si discosterà in positivo o in negativo dall’effettivo numero di alberi presenti nei 100 ettari. Se volessi ottenere un valore accurato dovrei contare gli alberi uno ad uno presenti nei 100 ettari, un lavoro decisamente oneroso in termini di tempi di risposta, per non pensare al caso che gli ettari anziché 100 fossero 1000 o più.
Allo stesso modo anche l’interfaccia di Google Analytics, in talune circostanze, applica il campionamento dei dati nei propri rapporti e questo deve essere assolutamente verificato quando si interroga la piattaforma. Infatti, a seconda delle finalità per le quali i dati verranno utilizzati e del livello di campionamento in corso, possiamo ottenere informazioni non rappresentative.
Come si capisce se Google Analytics ha applicato il campionamento
L’ultimo aggiornamento, lato interfaccia, che avvisa dello stato di campionamento è l’icona di uno scudo a fianco del nome del report, nella parte superiore della piattaforma.
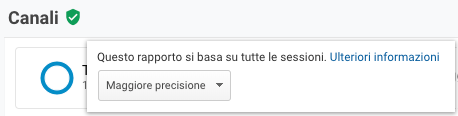
Se lo scudo è verde i rapporti si basano sul 100% dei dati, Fig. 1:
Altrimenti lo scudo è di colore giallo, e cliccando sull’icona appare un messaggio con indicata la percentuale di campionamento, Fig. 2:
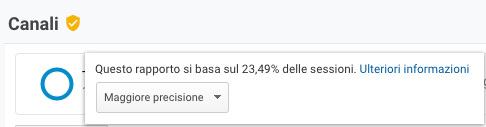
Nota: In alcuni casi lo scudo può essere giallo ma i dati non sono campionati. Questo può capitare quando si osservano report dove le righe della tabella sono state filtrate in modo da includere solo i dati relativi alla selezione effettuata (ad esempio “Categoria evento”), mentre il grafico e le intestazioni della tabella includono i totali di tutti i dati.
Quando Google Analytics applica il campionamento
Il campionamento dei dati può verificarsi quando si applicano segmenti, dimensioni secondarie o si filtrano i report di Google Analytics. Ogni volta che un rapporto standard viene modificato così come quando viene creato un rapporto personalizzato, Google dovrà interrogare i dati in modo dedicato, incrociando informazioni che non ha già a disposizione (come invece sono quelle dei report standard). Questo può portare al campionamento sulla base del numero di sessioni analizzate, in generale:
- Analytics Standard: 500.000 sessioni a livello di proprietà per l’intervallo di date utilizzato;
- Analytics 360: 100 milioni di sessioni a livello di vista per l’intervallo di date utilizzato.
Attenzione: Analytics potrebbe modificare nel tempo rapporti e modalità di calcolo delle metriche. Se l’intervallo di date di un rapporto include un periodo di tempo che precede questa modifica, necessitando di un’elaborazione dedicata, potrebbe restituire dati campionati.
Per questo motivo, con l’avvento di “Users Everywhere” (gli utenti al centro della strategia digital), se l’intervallo di tempo selezionato, nei rapporti che comprendono le metriche Utenti e Utenti attivi, comprende dati prima di settembre 2016, i dati vengono campionati.
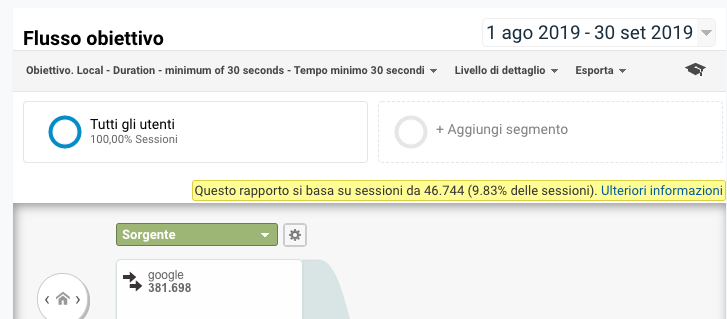
I rapporti di visualizzazione della navigazione (Flusso di utenti, Flusso di comportamento, Flusso eventi e Flusso obiettivo), a differenza degli altri rapporti, iniziano a campionare dopo le 100.000 sessioni sulla base dell’intervallo di date selezionato, Fig. 3, anche se si utilizza Google Analytics 360:
Anche i Rapporti canalizzazioni multicanale e di attribuzione seguono un campionamento a se stante. Modificando il rapporto standard viene restituito un campione massimo di 1 milione di conversioni.
C’è da fidarsi del campionamento?
Se dovessi pagare gli autori di articoli in un blog sulla base delle visualizzazioni di pagina che i loro articoli generano, sicuramente mi baserei su un valore riproducibile e confrontabile, ovvero le visualizzazioni di pagina del 100% delle sessioni. Se invece la risposta cercata nei dati è di tipo indicativo, ovvero capire in linea di massima l’ordine di grandezza del traffico generato da un sito, posso ritenere affidabile un campionamento superiore all’80-90%.
Percentuali di campionamento più basse sono del tutto inaffidabili. Nell’immagine seguente è mostrato, in un determinato intervallo, il numero di eventi totali ed unici di condivisione di articoli in un sito (ho appositamente incrociato un segmento ed il campionamento dei dati si basa sul 5,06% di sessioni), Fig. 4:
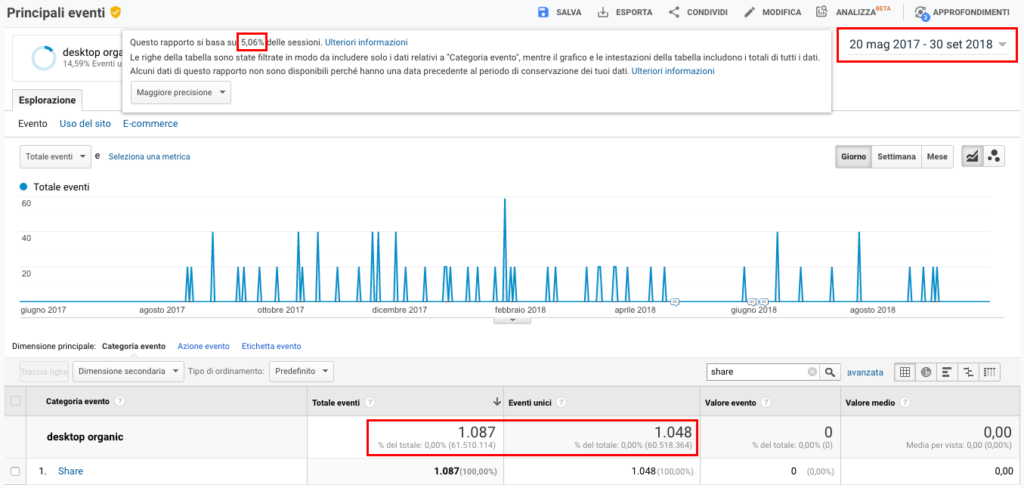
Risultano nel caso specifico 1.087 eventi totali e 1.048 eventi unici.
Aumentando l’intervallo di tempo di un mese mi aspetto che il numero di eventi sia uguale o superiore a quello appena visualizzato.
Quello che succede, invece, è mostrato in Fig. 5:
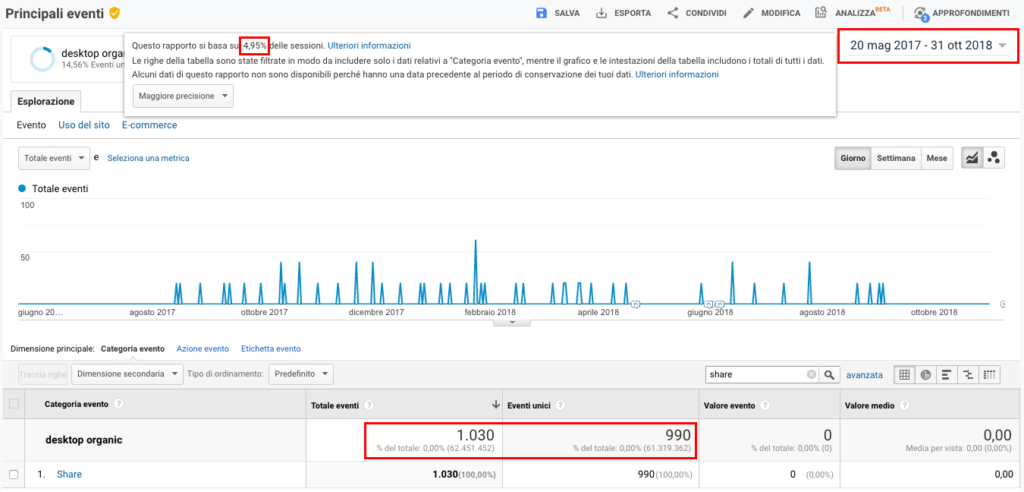
Aumentando di un mese il periodo selezionato, e quindi aumentano le sessioni, diminuisce la percentuale di sessioni su cui si basa il campionamento (da 5,06% a 4,95%). Il risultato è che il numero totale di eventi risulta ora 1.030 e quello di eventi unici 990.
Uno 0,11% di sessioni considerate in meno, rispetto ad una percentuale di sessioni già bassa in partenza, comporta che il numero di eventi totali (e unici), che per definizione può solo crescere col tempo (o rimanere uguale), è invece diminuito.
A scopo informativo, il reale numero di eventi totali e di eventi unici dell’esempio in Fig. 4, calcolato sul 100% delle sessioni, è rispettivamente 1.232 e 1.156. Un errore di circa il 20%, non trascurabile.
Soluzione
Personalmente preferisco lavorare sempre con dati basati sul 100% delle sessioni. Sono riproducibili e statisticamente più affidabili.
Di seguito alcuni consigli su come ottenere report con dati non soggetti a campionamento:
- Assicurarsi che non esistano effettivamente report standard che permettono di ottenere il risultato desiderato. Spesso capita di applicare segmenti o creare report personalizzati per ottenere un dato già presente all’interno dei report disponibili di Google Analytics.
- Ridurre l’intervallo di date, ad esempio mese per mese, per stare sotto la soglia delle 500.000 sessioni (in Google Analytics standard). Dopodiché esportare i dati e aggregarli in autonomia in un foglio di calcolo. È possibile automatizzare il processo con strumenti dedicati, ad esempio interrogando giornalmente le API di Google Analytics tramite uno script con Google Apps Script per generare report automatici e creandosi un archivio di dati non campionati ed elaborabili fuori dalla piattaforma di analisi.
- Migrare a Google Analytics 360. I rapporti saranno ancora soggetti a campionamento se pur con soglie decisamente più elevate, tuttavia esiste l’opzione di richiesta di report non campionati per ottenere il dato basato sul totale delle sessioni acquisite nel periodo selezionato.
Se hai avuto esperienze interessanti con il campionamento dei dati o se hai altri suggerimenti oltre a quelli appena descritti, lascia un commento qui sotto!
Commenti recenti